Elastic Cloud und Cross Cluster Search Cluster (CCS)
Flexible Elasticsearch Cross Cluster Search Cluster Konfiguration mit Elastic Cloud

Elastic Cloud?
Elastic bietet eine "Multi-Cloud" SaaS Lösung von Elasticsearch-basierten Produkten an. Mit Elastic Cloud lassen sich mit wenigen Mausklicks, redundante und produktionsbereite Elasticsearch Cluster hochziehen innerhalb von Minuten. Mehr Informationen könnt ihr hier finden: https://www.elastic.co/de/cloud/
Grosse Cluster sind schwieriger zu handhaben
Wer viele Daten mit Kibana und Elasticsearch verfügbar machen möchte, hat früher oder später ein Problem mit der Cluster-Grösse. Auch mit Elastic Cloud lassen sich die Cluster nicht unendlich gross ausbauen, ebenfalls kommen bei vielen Daten und Feldern unter Umständen auch Performance-Probleme hinzu. Hier sind ein Paar Probleme die auftreten können:
- Lange Zeiten beim Snapshot; Können zu Fehlern beim Löschen von Indexen mit Curator führen.
- Enorm viele Felder; Führen meisten zu vielen Konflikten und Aufwand bei der Template pflege und/oder reindexing von fehlerhaften Indexen.
- Viele Beats mit grosser
bulk_max_sizekönnen zu partial/full rejections führen bzw. Überforderung des Clusters. - Falsche Anzahl von Shards; Overhead und schlechtere Performance
- ... etc. Hier ist ein Artikel (Englisch) der die gesamte Problematik mit einigen Fragen aufzeigt: https://medium.com/kariyertech/elasticsearch-cluster-sizing-and-performance-tuning-42c7dd54de3c
Cross Cluster Search (CCS) Cluster
Um all die oben genannten Probleme zu umgehen, könnt ihr ein Cross Cluster Search Cluster einsetzen. Der CCS-Cluster bzw. Kibana nimmt alle Anfragen entgegen und sucht die jeweiligen Dokumente direkt bei den "Remote" Clustern wie folgende Grafik zeigt:
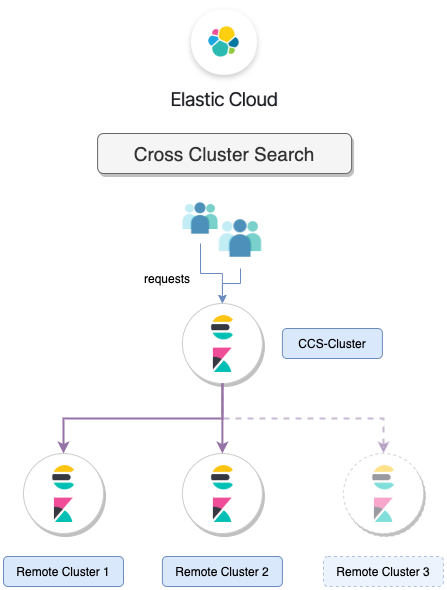
Diese Multi Cluster Architektur bringt einige Vorteile mit sich:
- Der CCS-Cluster erlaubt das Suchen von Dokumenten über alle Remote Cluster mithilfe von Index Patterns, die die Cluster Namen enthalten. Es kann aber auch gezielt auf einem Cluster, zwei Clustern, etc. gesucht werden, falls ein entsprechendes Index Pattern konfiguriert ist.
- Benutzer, Gruppen, Suchen, Dashboards, Visualisierungen, Watchers, Machine Learning Jobs, usw. werden in der Regel nur noch einmal auf dem CCS-Cluster eingerichtet und verwaltet.
- Aufteilung der einzelnen Remote Cluster nach Einsatzgebiet / Umgebung / Region usw. möglich.
- Aktualisierungen werden einfacher da die "Beaters" jeweils (temporär) auf einen anderen o. neuen Cluster umgeleitet werden können.
- Einfachere Handhabung der einzelnen Cluster wie Grösse ändern oder Skalierung.
- Performance/Konfiguration kann für die einzelnen Cluster und Anwendungsfälle gezielt verändert/angepasst werden. Der CCS-Cluster kann zum Beispiel mit 3 Kibana Nodes und mehr RAM - für mehr Performance - betrieben werden.
Mit Elastic Cloud lässt sich ein dedizierter Cross Cluster Search Cluster erstellen. "Cross Cluster Search" ist als Deployment Template verfügbar beim erstellen eines neuen Clusters:
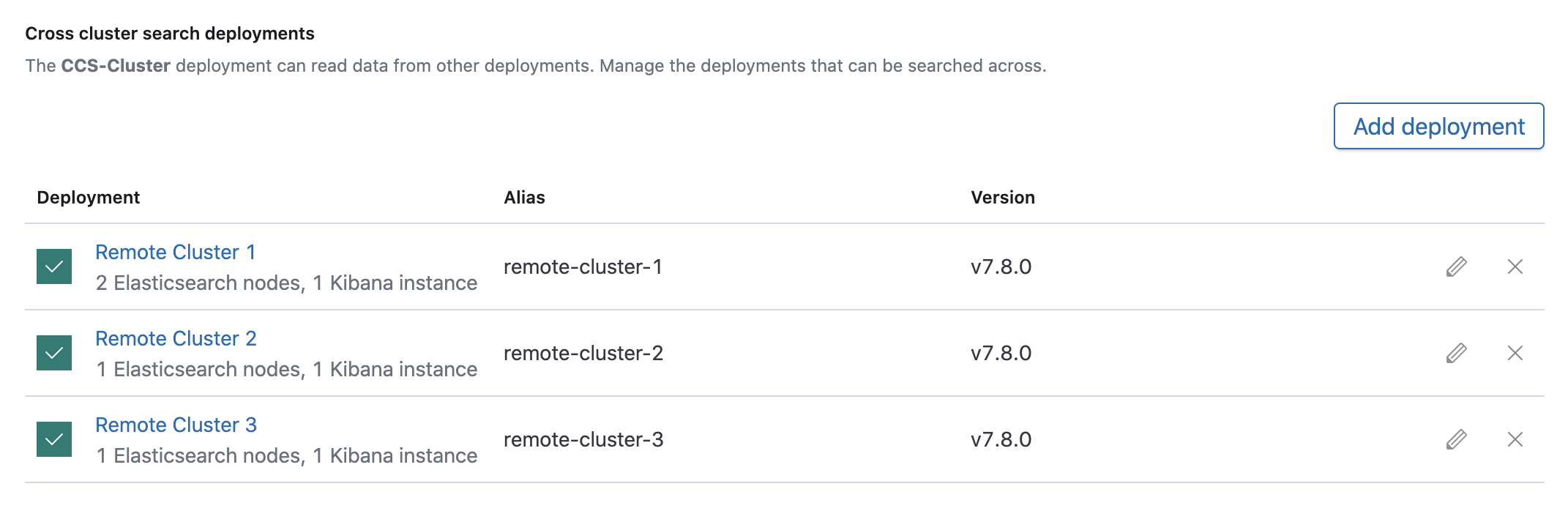
Diesem CCS-Cluster können nun andere Elasticsearch Cluster als Remote Cluster "angehängt" werden:
Index Pattern Beispiel
Das Index Pattern bestimmt auf welchem Cluster und Index gesucht werden soll.
Einrichten eines Filebeat Index Patterns mit den Remote Clustern remote-cluster-1, remote-cluster-2 und remote-cluster-3:
remote-cluster-1:filebeat-*,remote-cluster-2:filebeat-*,remote-cluster-3:filebeat-*Filebeat Index Pattern für genau einen Remote Cluster remote-cluster-1:
remote-cluster-1:filebeat-*Tipp: Index Pattern mit Wildcards im Cluster Namen
Index Pattern werden in Suchen, Visualisierungen und Dashboards gespeichert. Wenn ihr nun eine Cluster hinzufügt oder entfernt, müsst ihr das Index Pattern anpassen falls ihr die vollen Cluster Namen verwendet und somit ebenfalls alle gespeicherten Suchen, Visualisierungen und Dashboards. Um dies zu umgehen und um auch für zukünftige Mutationen das Index Pattern nicht ändern zu müssen, solltet ihr euch eine gute Namensgebung überlegen.
Ein Cluster Namenschema könnte so aussehen: logs01-stage, logs02-stage, logs03-stage und dasselbe für die Produktion logs01-prod, logs02-prod, logs03-prod, ... etc.. Ein geeignetes Index Pattern mit Wildcards im Cluster Namen wäre nun logs*:filebeat-*. Alle Suchen, Visualisierungen und Dashboards die ihr mit diesem Index Pattern erstellt, müssen nicht mehr angepasst werden und etwaige Mutationen an den Clustern sind automatisch berücksichtigt.