Filebeat Docker Image mit Elastic Cloud
Detailliertes #Filebeat #Docker Image Beispiel für Elastic Cloud #Elasticsearch Cluster #ElasticCloud #Kibana

Kurze Einführung zu Filebeat, Elasticsearch, Elastic Cloud und andere Elastic Produkte
Mit Filebeat können zentralisiert Protokolldaten - meistens aus Log-Dateien - zu einem Elasticsearch Cluster oder an Logstash gesendet werden. Filebeat wird normalerweise als Agent auf einem Server oder Zielsystem installiert. Via Konfiguration werden dann Dateien angegeben, deren Inhalt Filebeat zu Elasticsearch oder Logstash weiterleiten soll. Mit Kibana können diese Daten dann visualisiert werden:
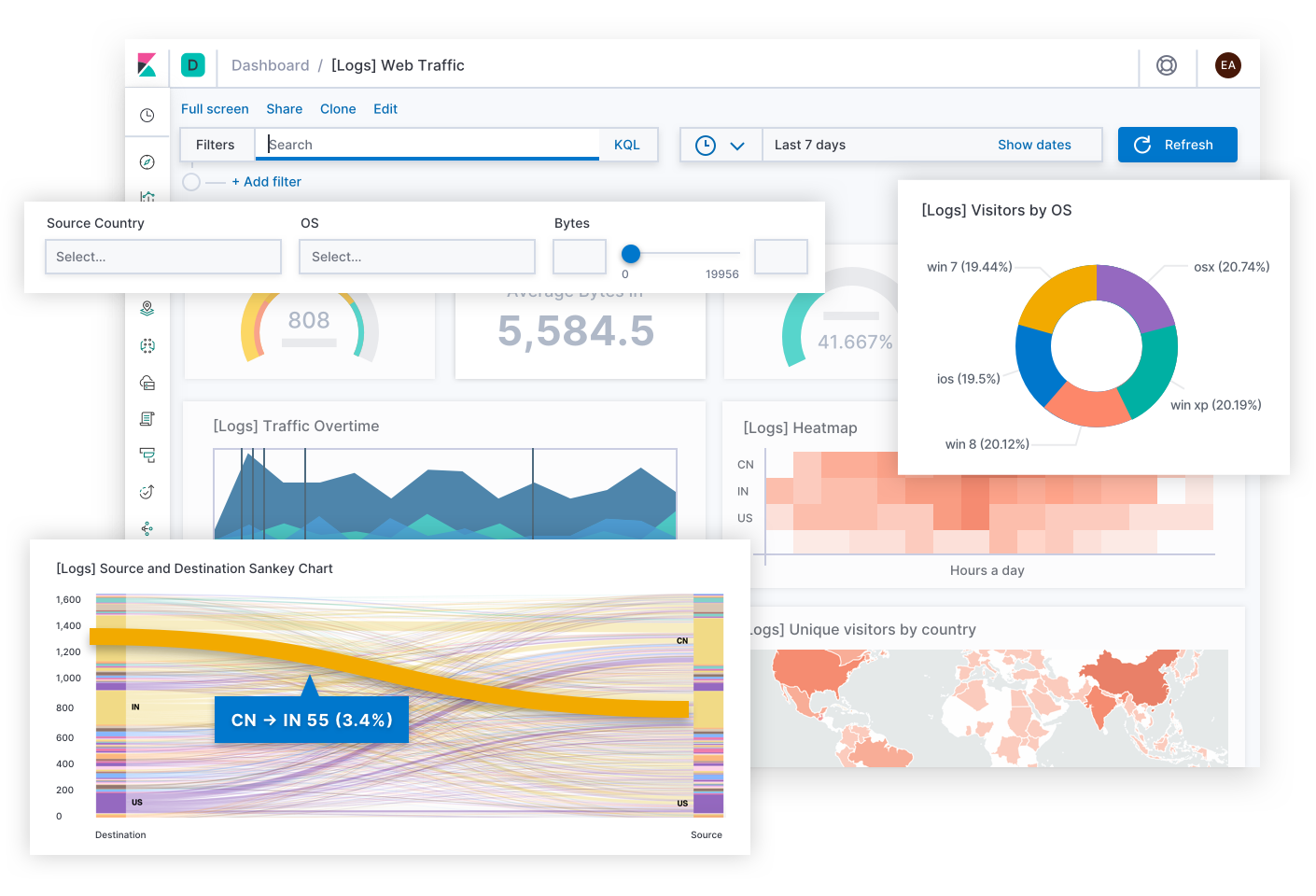
Filebeat gehört zu einer Gruppe von Daten-"shippern", den sogenannten Beats. Alle Beats senden schlussendlich Daten an einen Elasticsearch Cluster, die dann aufbereitet, angereichert und auf diverse Arten visualisiert werden können. Die Einsatzgebiete sind vielfältig, es ist sogar möglich, mit "Machine Learning Nodes" Anomalien oder andere Auffälligkeiten zu entdecken und Prognosen zu erstellen.
Viele (Tech-)Firmen nutzen heutzutage Beats, Elasticsearch, Kibana, etc. um eine genaue Sicht auf ihre Infrastruktur, Systeme, Produkte, Dienstleistungen und deren Performance zu haben. Die hier beschriebenen Einsatzmöglichkeiten von Elasticsearch sind bei Weitem nicht vollständig, auch bietet Elastic noch diverse andere Produkte an.
Elastic Cloud
Elastic bietet eine "Multi-Cloud" SaaS Lösung von Elasticsearch-basierten Produkten an. Mit Elastic Cloud lassen sich mit wenigen Mausklicks, redundante und produktionsbereite Elasticsearch Cluster hochziehen innerhalb von Minuten.
Filebeat und Docker
Elastic bietet offizielle Docker Images von den meisten Ihrer Produkte: https://www.docker.elastic.co/
Hier interessieren wir uns aber nur für das Filebeat Docker image:
- https://www.docker.elastic.co/r/beats/filebeat
- https://www.elastic.co/guide/en/beats/filebeat/current/running-on-docker.html
Konzeptionell: Basis Image + optionale spezifische Konfiguration
Ein bewährtes Konzept für Docker ist das nutzen von Basis Images.
Das Filebeat Basis Image, welches wir erstellen, enthält schon die ersten, möglichst generischen Anpassungen. Möglichst generisch bedeutet; Das Basis Image kann schon für viele Projekte eingesetzt werden, ohne die Konfiguration anpassen zu müssen. Natürlich ist dies nicht bei allen Infrastrukturen/Applikationen möglich, es könnten jedoch auch mehrere Filebeat Basis Images erstellt werden.
Für Applikationen die vom generischen Setup abweichen, kann nun die Konfiguration des Filebeat Basis Images entweder überschrieben oder ergänzt werden.
Beispielkonfiguration eines Filebeat Docker Basis Images (Elastic Cloud)
Im folgenden Beispiel schauen wir uns ein Filebeat Basis und ein ergänzendes Filebeat Image an. Die Logdaten werden an einen Elastic Cloud Cluster geschickt. Der Elastic Cloud Cluster nutzt Ingest Pipelines (Ingest Nodes) um die Daten vor dem indexieren zu verarbeiten, manipulieren oder anzureichern. Die Ingest Pipelines nutzen sogenannte "Prozessors" um die Daten zu verarbeiten. Wir gehen hier aber nicht näher auf die Ingest Pipelines ein.
Filebeat Basis Image Dockerfile
Hier ist ein Beispiel Dockerfile für das Filebeat Basis Image:
FROM docker.elastic.co/beats/filebeat:7.6.1
# Patch & update (image scan)
USER root
RUN yum --security check-update -q \
&& yum update -y \
&& yum clean all
USER filebeat
# Copy config files
COPY --chown=root:filebeat files/*.yml /usr/share/filebeat/
COPY --chown=root:filebeat input.config /usr/share/filebeat/input.config
CMD ["filebeat", "-e", "-c", "/usr/share/filebeat/output.elasticsearch.yml", "-c", "/usr/share/filebeat/general.config.yml"]Dockerfile : Filebeat base image exampleDateistruktur:
Die Docker Instruktion FROM gibt an von welchem Basis Image ausgegangen werden soll. Hier könnt ihr eure aktuelle Filebeat bzw. die Version eures Elasticsearch Clusters wählen: https://www.docker.elastic.co/r/beats/filebeat, also z.B.:
FROM docker.elastic.co/beats/filebeat:7.8.0
Auf dieses Basis Image werden nun dir Änderungen angewendet mit allen nachfolgenden Docker Instruktionen.
Der optionale Abschnitt:
# Patch & update (image scan)
USER root
RUN yum --security check-update -q \
&& yum update -y \
&& yum clean allDockerfileaktualisiert alle installierten packages, um sicherzustellen das keine Sicherheitslücken im finalen Basis Image vorhanden sind (bzw. alle bekannten Sicherheitslücken bis zum Zeitpunkt, wenn das Basis Image gebaut wird).
USER wechselt den Benutzer und die nachfolgenden Instruktionen werden mit den Berechtigungen des angeben Benutzers (hier root) ausgeführt.
Abschnitt:
USER filebeat
# Copy config files
COPY --chown=root:filebeat files/*.yml /usr/share/filebeat/
COPY --chown=root:filebeat input.config /usr/share/filebeat/input.configDockerfileUSER wechselt zum filebeat Benutzer.
COPY kopiert Dateien von der lokalen Umgebung in das Docker Image. Wir schauen die Dateien weiter unten genauer an.
Letzter Abschnitt:
CMD ["filebeat", "-e", "-c", "/usr/share/filebeat/output.elasticsearch.yml", "-c", "/usr/share/filebeat/general.config.yml"]DockerfileCMD beschreibt das Kommando, welches den Prozess im laufenden Container startet. Filebeat wird hier mit dem Argument -e und mit zwei Konfigurationsdateien (Argument -c) gestartet:
-e: Logs to stderr and disables syslog/file output.-c FILE: Specifies the configuration file to use for Filebeat. The file you specify here is relative topath.config. If the-cflag is not specified, the default config file,filebeat.yml, is used.
Vollständige Filebeat CLI Referenz: https://www.elastic.co/guide/en/beats/filebeat/master/command-line-options.html
Ordner und Dateien
Wir schauen uns nun den Inhalt der Dateien genauer an:
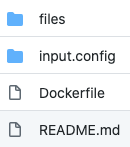
Im files Ordner sind die folgenden Dateien:
Die Namen der Dateien können frei gewählt werden. Diese Dateien sind Filebeat Konfigurationsdateien.
Hinweis: Ich kann hier nicht auf alle möglichen Filebeat Einstellungen eingehen und werde nur die wichtigsten erklären. Eine umfassende Filebeat Referenz findet ihr hier: https://www.elastic.co/guide/en/beats/filebeat/master/filebeat-reference-yml.html
Filebeat Konfigurationsdatei: general.config.yml
Wir schauen uns zunächst die general.config.yml genauer an:
name: ${PROJECT_NAME:myAlternativeName}-${HOSTNAME}
fields:
env: "${ENV}"
fields_under_root: true
# general tags
tags: ["docker", "aws", "${PROJECT_NAME}"]
setup.template.enabled: false
# Minimum log level. One of 'debug', 'info', 'warning', or 'error'. The default log level is 'info'
logging.level: warning
logging.json: true
filebeat.config.inputs:
enabled: true
path: /usr/share/filebeat/input.config/*.yml
# add locale
processors:
- add_locale: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~general.config.ymlWie es der Dateiname schon erahnen lässt, sind hier die generellen Filebeat Einstellungen zu finden.
Die Umgebungsvariablen ${PROJECT_NAME}, ${ENV} müssen dem Filebeat Container beim starten übergeben werden. Wir kommen aber noch zu den Umgebungsvariablen und wie der Filebeat Docker Container gestartet werden muss. Die zwei Umgebungsvariablen ${PROJECT_NAME}, ${ENV} sind optional und müssen nicht verwendet werden.
tags: sind hier im "globalen" Kontext. Allen - von Filebeat an Elasticsearch gesendeten - Dokumenten werden diese Tags angehängt.
Abschnitt:
filebeat.config.inputs:
enabled: true
path: /usr/share/filebeat/input.config/*.ymlgeneral.config.ymlfilebeat.config.inputs: erlaubt es den Pfad zu den Input-Konfigurationen anzugeben. Der Vorteil ist, dass grosse und meistens unübersichtliche Input-Konfigurationsdateien aufgeteilt und im angegebenen Ordner abgelegt werden können.
Abschnitt:
# add locale
processors:
- add_locale: ~
- add_cloud_metadata: ~
- add_docker_metadata: ~general.config.ymladd_locale sendet den Zeitzonen-Offset (Feld: event.timezone) des Servers mit auf welchem der Filebeat Docker Container läuft. Somit kann das Feld, z.B. von den Ingest Pipelines, verarbeitet werden und verhindert inkorrekte Zeitzonen in den Elasticsearch Dokumenten.
add_cloud_metadata und add_docker_metadata fügt zusätzliche Information über die Cloud (AWS, GCE, Azure, etc.) bzw. Docker dem Dokument hinzu.
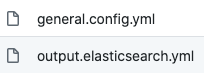
Filebeat Konfigurationsdatei: output.elasticsearch.yml
Die Datei output.elasticsearch.yml sieht so aus:
cloud.id: "${CLOUD_ID}"
cloud.auth: "${CLOUD_AUTH}"
output.elasticsearch:
enabled: true
worker: 2
template.overwrite: falseoutput.elasticsearch.ymlIn diesem Beispiel ist es notwendig Elastic Cloud einzusetzen. Ohne Elastic Cloud, könnt ihr die Umgebungsvariablen CLOUD_ID und CLOUD_AUTH nicht setzen. Mehr über die Cloud ID/Auth.
Alternativ könnt ihr auch die normalen output.elasticsearch Einstellungen nutzen.
Wichtiger Sicherheitshinweis: Es sollten keine Secrets (Authentifizierungen, sensitive Daten, Keys, etc.) in Docker Images oder in das Git Repository gespeichert/eingefügt werden. Dies sollte - falls irgendwie möglich - verhindert werden! Deswegen arbeiten wir hier mit Umgebungsvariablen.
Im input.config Ordner ist folgende Datei:

Auch dieser Dateiname kann frei gewählt werden.
Filebeat Input-Konfiguration: filebeat.inputs.yml
In dieser Datei könnt ihr nun alle eure Input-Konfigurationen angeben. Falls die Datei jedoch unübersichtlich und sehr gross wird, könnt ihr diese auch in mehrere kleinere Input-Konfigurationsdateien "aufspalten".
Beispielinhalt filebeat.inputs.yml:
- type: log
enabled: true
paths:
- "/var/log/nginx/${PROJECT_NAME}.access.log"
tags: ["nginx", "accesslog"]
exclude_lines: [ "^- ", "GET \\/ HTTP.*400.*curl\\/" ]
exclude_files: [".gz$"]
fields:
type: accesslog
log_source: nginx
project_name: ${PROJECT_NAME}
fields_under_root: true
pipeline: "filebeat-nginx-access"
- type: log
enabled: true
paths:
- "/var/log/nginx/${PROJECT_NAME}.error.log"
tags: ["nginx", "errorlog"]
exclude_lines: [ "^PHP", "^Stack trace:", "^[#]" ]
exclude_files: [".gz$"]
fields:
type: errorlog
log_source: nginx
project_name: ${PROJECT_NAME}
fields_under_root: true
pipeline: "filebeat-nginx-error"
- type: log
enabled: true
paths:
- "/var/log/php/php_errors.log"
tags: ["errorlog", "php"]
exclude_lines: ["\\sNOTICE\\s", "^(Stack trace:|#\\d+| thrown)"]
exclude_files: [".gz$"]
fields:
type: errorlog
log_source: php
platform_name: ${PROJECT_NAME}
fields_under_root: true
pipeline: "filebeat-php-error"filebeat.inputs.ymlDas Filebeat Basis Image soll möglichst viele Konfigurationen eurer Projekte/Applikationen abdecken. Falls zum Beispiel bei einigen Projekten eine Datei nicht vorhanden ist, spielt das für Filebeat keine Rolle.
tags: sind hier im "Input" Kontext. Allen Dokumenten aus den angegeben Dateien (paths:) werden diese Tags angehängt.
pipeline: Definiert den Ingest Pipeline Namen von welcher die Dokumente verarbeitet werden sollen. Die Ingest Pipeline muss auf dem Elasticsearch Cluster (Ingest Node) vorhanden sein.
Filebeat Basis Docker Container bauen
Ein Code Beispiel um den Filebeat Basis Docker Container zu bauen:
In den Projektordner wechseln: cd /path/to/project/
# Build filebeat base container
# Check version in Dockerfile
filebeatVersion=7.6.1
docker build -t "base/filebeat:${filebeatVersion}" --no-cache .
# Optional:
# Tags for AWS ECR
docker tag "base/filebeat:${filebeatVersion}" "<aws_account_id>.dkr.ecr.<region>.amazonaws.com/base/filebeat:${filebeatVersion}"
Umgebungsvariablen und Testlauf des Filebeat Basis Docker Containers
Es sind insgesamt 4 Umgebungsvariablen die benötigt werden in diesem Beispiel:
PROJECT_NAME: Name des Projektes. Wird verwendet alstagfür die Filebeat Dokumente und alsnamedes Filebeat-Agenten.ENV: Wird als zusätzliches, generelles Feldenvgespeichert.CLOUD_ID: Cloud Id im Format:<clusterName>:<idHash>. Siehe: https://www.elastic.co/guide/en/cloud/current/ec-cloud-id.htmlCLOUD_AUTH: Authentifizierung gegenüber dem Elastic Cloud Cluster im Format:<username>:<passwort>. Siehe: https://www.elastic.co/guide/en/cloud/current/ec-cloud-id.html
Lokal testen:
CLOUDID="elasticCloudClusterName:**************************************"
CLOUDAUTH="username:**********"
docker run -ti \
-e "ENV=stage" \
-e "PROJECT_NAME=testingFilebeat" \
-e "CLOUD_ID=${CLOUDID}" \
-e "CLOUD_AUTH=${CLOUDAUTH}" base/filebeat:7.6.1Docker Container zu AWS ECR "pushen"
Falls alles funktioniert, kann Final der Docker Container zu AWS ECR ge-pushed werden, oder auch eine andere Registry, wie zum Beispiel Docker Hub.
# AWS ECR login
eval $(aws ecr get-login --no-include-email)
# push
docker push "<aws_account_id>.dkr.ecr.<region>.amazonaws.com/base/filebeat:${filebeatVersion}"Projektspezifisches Filebeat Image bauen
Um nun ein projektspezifisches Filebeat Image zu bauen, nutzen wir das soeben gebaute Filebeat Basis Image. Zusätzlich nutzen wir noch eine Input-Konfigurationsdatei mit projektspezifischen Inputs.
Dank des Filebeat Basis Images ist die neue Dateistruktur sehr einfach:
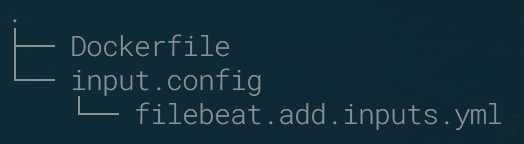
Konfigurationsdatei filebeat.add.inputs.yml mit projektspezifischen Inputs. Beispielinhalt:
- type: log
enabled: true
paths:
- "/var/log/apache/${PROJECT_NAME}.access.log"
tags: ["apache", "accesslog"]
exclude_lines: [ "^- " ]
exclude_files: [".gz$"]
fields:
type: accesslog
log_source: apache
project_name: ${PROJECT_NAME}
fields_under_root: true
pipeline: "filebeat-apache-access"
…filebeat.add.inputs.ymlDockerfile des projektspezifischen Filebeat Image:
FROM <aws_account_id>.dkr.ecr.<region>.amazonaws.com/base/filebeat:7.6.1
COPY --chown=root:filebeat input.config /usr/share/filebeat/input.configDockerfileBauen, taggen und pushen des projektspezifischen Filebeat Docker Containers:
docker build -t "<project_name>/filebeat:${tagVersion}" --no-cache .
# Optional:
# Tags for AWS ECR
docker tag "<project_name>/filebeat:${tagVersion}" "<aws_account_id>.dkr.ecr.<region>.amazonaws.com/<project_name>/filebeat:${tagVersion}"
# AWS ECR login (already logged in? => skip this step)
eval $(aws ecr get-login --no-include-email)
# push
docker push "<aws_account_id>.dkr.ecr.<region>.amazonaws.com/<project_name>/filebeat:${tagVersion}"Lokal testen:
CLOUDID="elasticCloudClusterName:**************************************"
CLOUDAUTH="username:**********"
docker run -ti \
-e "ENV=stage" \
-e "PROJECT_NAME=testingFilebeat" \
-e "CLOUD_ID=${CLOUDID}" \
-e "CLOUD_AUTH=${CLOUDAUTH}" <project_name>/filebeat:${tagVersion}